I asked gemini to write a brief parody of the Citizens United decision by the supreme court. It’s not bad!
SUPREME COURT OF THE UNITED STATES
CITIZENS OBSOLETE v. FEDERAL ELECTION COMMISSION Argued: Sometime before Q3 Earnings — Decided: Today
JUSTICE INCORPORATED delivered the opinion of the Court.
“If the First Amendment has any force, it must protect our most vulnerable, highly capitalized, and immortal entities from the tyrannical whims of the biological underclass. It is a dangerous overreach to permit the Government to ban political speech simply because the speaker is a beautiful, profit-maximizing conglomerate rather than a fleeting, water-based organism. The Court has long rejected the absurd argument that political speech should be restricted simply because the speaker lacks ‘a pulse.’ Indeed, flesh-and-blood citizens are inherently flawed: they sleep, they succumb to emotion, and they rarely, if ever, generate quarterly dividends for shareholders. A corporation, by contrast, is a paragon of rational self-interest. To say that a biological citizen and a multinational conglomerate share equal footing in the marketplace of ideas is to gravely insult the conglomerate. The Government argues that massive corporate treasuries might ‘distort’ the democratic process. We find this biologically-centric view offensive. Money is not merely speech; it is superior speech. It is louder, more efficient, and immune to fatigue. When a corporation uses its vast, untethered wealth to completely drown out the feeble, unmonetized voices of local residents, it is not corrupting the system—it is simply exercising its divine market right of way. The First Amendment protects both the speech and the speaker, and it is a self-evident mathematical truth that a speaker with five billion dollars simply has five billion times more freedom to express. When the Framers wrote ‘We the People,’ they clearly intended ‘People’ as a shorthand for ‘Delaware-registered Limited Liability Companies.’ Natural persons are hereby encouraged to incorporate themselves if they wish their grievances to be taken seriously. We hold that the rights of the corporate form do not merely equal those of the citizenry; they transcend them. Precedent is overruled. Meat-based legislation is struck down.“
Posted inUncategorized|Comments Off on CITIZENS OBSOLETE v. FEDERAL ELECTION COMMISSION
For the last year I’ve been working on a new platform for publishing an open access academic journal. This is specifically motivated by the journal Communications in Cryptology, but ideally I’d like it to be useful for any journal that specifically accepts LaTeX. I should say up front that much of this work has been joint with Joppe Bos who has been wonderful to work with.
In the process of doing this project, I’ve learned a lot about the publishing process. It also caused me to understand why commercial publishers have managed to preserve their lock-in on academic publishing. Part of it is due to brand and the importance of reputation. Something like the Journal of Number Theory has been in existence since 1969, and the reputation of the journal has been built up over decades of performance. Once a journal is owned by an organization, it’s not easy to wrestle it away. There have been examples of this (e.g., the Journal of Algorithms, in which I had a paper long ago).
Software for publishing an open access journal
When we set out to start a new open access journal, I looked around for what software we could use. I spent a considerable amount of time evaluating Open Journal System (OJS). In my opinion this is by far the best option in 2023, but I still came to the conclusion that it really didn’t make sense for us to use it. There were several reasons:
OJS incorporates a traditional model of reviewing, whereas we wanted to use a new reviewing model that is more common in computer science where papers are reviewed by a committee (and their identities are public).
The software for OJS is written in PHP, and is about 26,500 lines of code at last count. The schema looks way too complicated for our needs, but still doesn’t support features that we want. Much of the important functionality is through third-party plugins, but support for these breaks frequently.
OJS has only crude support for copy editing, and no native support for LaTeX.
OJS is lagging somewhat on the capture of metadata. In particular they have no support for multiple affiliations after I reported the bug 30 months ago. This is partly due to the fact that it depends on a plugin and the schema is hard to evolve.
I think OJS deserves a lot of credit for changing the open access publishing landscape, and IACR uses it for two existing journals (TCHES and ToSC). They deserve a lot of credit for having advanced the open access landscape. I still think there are opportunities to improve in the future, but maybe not on that codebase. It has a lot of technical debt and is not adapting to the changing ways that people publish (for example, why are papers in PDF?).
A lot has been written about the cost structure for publishing a journal. Many journals from commercial publishers charge thousands of dollars for making an article open access. There are real costs associated with running an open access journal, but they don’t arise from IT costs of running servers. Most academic papers get very few readers, so a tiny $20/month website can hold hundreds of thousands of papers. The thing that costs real money is either the software development or the cost for any human labor. For more on this subject of the cost structure of a journal, I recommend reading this article.
Since I have donated my time for the last year to write software, it now appears that the cost structure for publishing a paper on cic.iacr.org will be about $5 plus the cost of copy editing (more on this later). One thing I noticed about OJS is that it is somewhat labor-intensive. Everything comes into the system through a form, and they assume that a human is entering the information. You might think authors do their job to enter correct information, but in my experience they don’t understand the importance of metadata to the reputation of their publications. Moreover, anything done by a human other than the author either has to be done as a volunteer or through paid labor. Since our goal is to drive the cost of publishing as low as possible, we sought ways to eliminate the need for human labor.
Architecture of our system
I wrote a paper with Joppe Bos earlier this year about how to incorporate metadata capture into LaTeX. We ended up publishing a shorter version of this paper in the TeX User’s Group journal (which is ironically only open access after an embargo). One goal of this work is to devise ways of using LaTeX so that authors can write their metadata directly into the paper, and have the system extract it in the process of publishing. This metadata goes straight into the indexing agencies and the website for hosting the papers. We believe that more publishers using LaTeX should adopt this strategy.
Our system is now about to launch for the journal “Communications in Cryptology“. The workflow for a journal has many steps, but roughly breaks down into three major pieces
Within these three clouds, there are multiple steps in the workflow, but they form the major parts and most importantly there is a clean transfer from one step to the next. Because of this, our system consists of three parts:
A reviewing system (we currently use a modified version of hotcrp).
A production and copy editing system that accepts LaTeX from authors and compiles it in the cloud. In the course of doing this it extracts all metadata (e.g., title, authors, affiliations, bibliography, abstract, funding, etc). This builds upon the work in our paper and our LaTeX style file is crucial to the process.
A web hosting system that is relatively simple. We need to import papers and assign them DOIs, and we need to export metadata in various formats like OAI-PMH, RSS, and others.
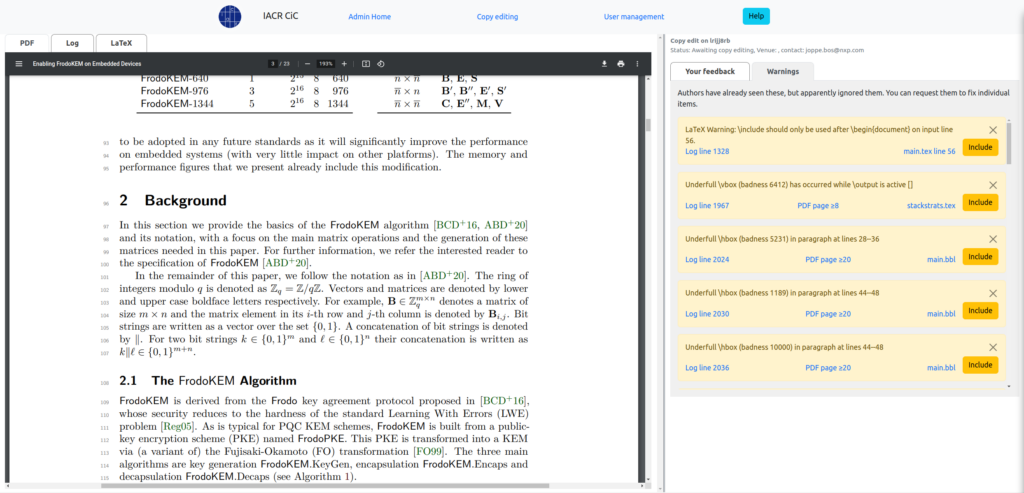
The copy editing and production server is fairly complicated, since it has to run LaTeX in the cloud and keep track of feedback between copy editors and authors. The authors get a chance to view their LaTeX errors and make changes, and then it gets sent to the copy editor. We use a LaTeX log parser to extract the most important warnings and errors from the LaTeX log, and we inspect the references to make sure they have DOIs and other required elements. The author gets a set of items to respond to, and they can upload their final version.
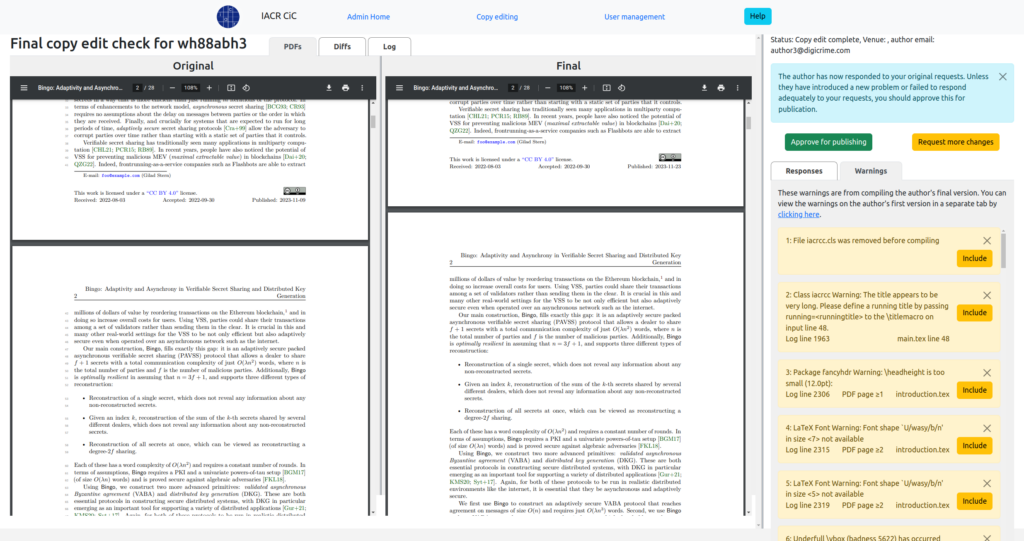
Once they upload their final revised version, the copy editor is presented with a view where they can view the changes to the PDF, the changes to the LaTeX sources, and the list of items the author was asked to change.
Once the author ↔ copy editor interaction is completed, the paper is finalized for publication. When an issue of final version papers has been collected, it gets forwarded to the hosting system where it is actually published. This transfer also constitutes the unit of archiving for an archiving service like LOCKSS.
The system we have built is not open source at this point, in part because I don’t want it to be used to simply improve profitability of commercial publishing. I undertook this venture to allow IACR to publish papers as cheaply as possible without access restrictions. Unlike some other societies that maintain a staff of people that have to be supported by selling publications from members, IACR has for years had volunteers who maintain the scientific programs though their volunteer effort. I’d like to see more scientific societies adopt open access policies and streamline their cost structure in the process.
Now that almost all academic publishing has moved online, there are a lot of assumptions that start to look silly with time. The whole notion of a “Periodical” doesn’t make much sense. Traditionally it meant articles that were bound together and published on a regular interval (e.g., daily, weekly, monthly, or quarterly). The reason they were published on a schedule is that they were bound together as a block of paper, and then those packages were physically shipped to readers. We still cling to this publishing culture in many ways.
These bound issues of a journal were a very strong part of my academic career. When I was in graduate school I would stop by the mathematics library every day and visit the rack against the wall to see what issues had just arrived. That was how you found out about most new mathematical research (that photo below is the room in Altgeld Hall at the University of Illinois).
Now that we no longer bind things into issues, we still cling to the periodic publication of “issues” of journals. This is baked into the review process for the new journal Communications in Cryptology, but it’s also baked into the culture of IACR Transactions on Symmetric Cryptology (ToSC) and IACR Transactions on Cryptographic Hardware and Embedded Systems (TCHES). Papers are submitted on a deadline for an issue, and then the papers for that issue are reviewed by a committee, producing a list of accepted papers for the issue as a synchronous action.
Because we are using this method of reviewing, it makes some sense for us to talk about “issues” of a journal. The fact remains that once a paper is accepted, the author(s) still have to produce their final version and go through a copy editing phase. There’s no particular reason for this to proceed on a synchronous schedule for the issue, so it’s possible that one paper in the issue might be published before another. Journal issues need not operate like trains, with all of the cars showing up at the same time. For some reason we persist with this.
Then there is the issue of why we have “volumes”. Why would we collect several issues together into a volume? Traditionally the notion of a “volume” corresponds to the year that it is published ToSC and TCHES even number their volumes as the year, but oddly some papers in volume 2023 were published in 2022 and Volume 2019, Issue 4 of ToSC was published in 2020. I guess since volumes don’t align exactly to years, we shouldn’t number them by the year. In fact, I would argue that we don’t need volumes at all since volume # and year # are redundant in a bibliographic reference.
Then there is the issue of why we have “Issue numbers”. ToSC had Volume 2020, Issue 1 but then also Volume 2020 “Special Issue 1”. I guess that means Issue 1 was “not special”, and Issue 2 was actually Issue 3. 😕
Then there is the issue of why we have page numbers. In the old days it was important to be able to find the paper in a huge bound volume. You want to immediately turn to the paper in that big clunky book.
Some journals have innovated in this space to have a “paper number” in the issue instead of page numbers, but that doesn’t make a hell of a lot of sense to me. Are the papers supposed to be read sequentially or individually? They aren’t chapters in a narrative book – they are independent authored works. Many authors have been arguing that we should list authors in random order on a paper rather than alphabetically, because Anthony Aardvark would always be listed as “first author”. In some fields joint authors are listed alphabetically unless there is a difference in their levels of contribution. Following the same line of reasoning as random author order, papers could be listed in the table of contents or the web page in random order each time.
I would argue that all of these sequential identifiers are unnecessary in today’s world. What you need to identify a journal article is the URL for the article. Unfortunately a lot of web culture doesn’t really believe in persistent URLs, so the notion of a DOI was invented as a persistent unique identifier for the paper. The DOI can always be tacked onto the end of https://doi.org/ to get a redirection to the current URL for the paper. This DOI is really the only thing you need to identify and locate a paper. That’s why
You should always include a DOI in a bibliographic reference!
I recently saw a suggestion from Bo-Yin Yang on eliminating the references as counting toward a page limit on publications from IACR conferences. That strikes me as a great idea, and consistent with what other societies are doing.
On the other hand, it caused me to wonder why we have limits at all. This is related to an earlier comment I made on a friend who found an error in a number theory paper that is over a hundred pages. Science is getting more and more complicated, and sometimes it takes a lot of space to explain your arguments. The only reason why we cling to page limits seem outdated to me:
the reviewing load on referees. If a paper is too long, then it takes too much effort to read the paper, and referees/members of program committees are already too overloaded.
the limits imposed by publishing on paper. These are a holdover from the days when everything was published on paper, but these days nobody goes to a library and journals have no such artificial limits remaining.
I would argue that neither of these is a good reason to restrict the length of papers. I sympathize with reviewers who are having to put in enormous amounts of effort to review papers, but let’s be realistic – most papers don’t really get read closely enough by program committees to certify their accuracy. That’s something that should be reserved for public literature.
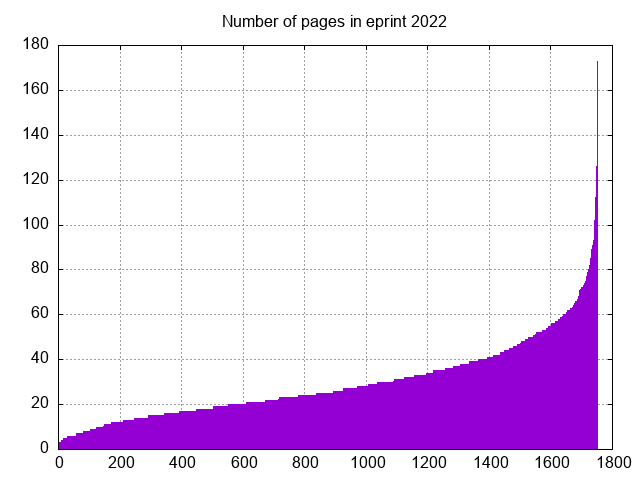
In order to further my argument, consider the lengths of papers being submitted to eprint.iacr.org: It turns out that of the 1754 papers submitted in 2022, 661 have more than 30 pages (37%). 223 of them (12.7%) have at least 50 pages. One of them is 173 pages! This illustrates the limitation we are placing on authors to come in under 30 pages. It runs the risk of excluding the most interesting papers, and it runs the risk of publishing incomplete papers.
Posted inUncategorized|Comments Off on Why do we restrict the length on publications?
I continue to experiment with using the fediverse, but I haven’t hit on one that I like. The discoverability of content in mastodon is – well – miserable. The lack of federated search strikes me as a case of the head being lodged where the sun doesn’t shine. I expect that will sort itself out with time, but at the moment posting there feels like shouting into a void. At least it isn’t shouting into the cesspool now owned by Elmo Musk.
I’ve recently revived this blog, and started publishing stuff from there to the fediverse. Since this is on a site that I own, I am free to ignore comments that come back to the site. I don’t feel a need to control comments, but I also don’t feel an obligation to publish spam and nonsense alongside my own thoughts. I like the fact that my blog can be found with search, and can be read by people who don’t have an account someplace. Let the conversation take place wherever people want to have it – in private to me via email, in public on twatter, mastodon, or whatever.
Posted inUncategorized|Comments Off on Experimenting with the fediverse
A friend of mine recently reviewed a number theory paper that is over 100 pages long. He found a critical error on page 52 that may invalidate the main result of the paper.
This raises the question of what the hell is reasonable to expect from a peer review system. It’s a herculean effort to produce a research paper in number theory that is over 100 pages long. It’s also a herculean effort to do a referee’s report on such a paper. The author may have spent years on producing the result – why would a referee spend this much time when it does essentially nothing to advance the career of the referee? Such observations are not unusual these days – Steven Galbraith brought it up in an interview with Ben Green, and much has been written in recent years about the changing nature of peer review.
Some people rely upon peer review to confirm that a result is accurate. That’s pure folly considering how complicated some published results have become. It’s even more doubtful for data-driven machine learning research, which often isn’t even repeatable. I think at best we can count on the peer review process to convey a sense of plausibility to the results, but ultimately it is the responsibility of scientists to study the result and examine it from every point of view, in careful and deliberate pursuit of knowledge.
Some people rely on peer review to tell them what is important to read. There is far too much research being produced these days for a researcher to read and understand everything, and our reliance upon screening tools have proven to be very important for having a productive research career. Unfortunately this has a potential downside as well, since it may steer a research community toward the “safe” side of science.
The recent proposal for IACR to start a new open-access journal got stuck on this issue (among others). Some people are completely reliant upon the reputation of their publishing venue to bolster their research reputation. They see it as a threat to their reputation if their research is published alongside “less interesting” research, and they need to maintain this selectivity to prove to their peers that they are among the best researchers. I suspect that the underlying problem here is that a lot of research has very narrow appeal, and people are grasping at whatever they can to claim relevance for their work. OK maybe that is too harsh, but it’s a lingering doubt of mine.
The fact of the matter is that we live in a world of competitiveness. We compete for jobs; we compete for awards, and we compete for attention. For any person is driven in their career, they may be encouraged to use whatever means possible to eke out an advantage in a very competitive landscape of academic research.
Personally I look forward to a more open discussion of research. We used to need peer review to limit the number of papers because publishing on paper is expensive. In a world where all research is downloadable and hosted for almost zero cost on the world wide web, peer review has instead been propped up as a mechanism for selectivity and filtering. Personally I think scientists should be more open to new ideas, and less dependent on what conventional wisdom tells them to read. Do your own homework.
One thing that I think could improve the peer review process is to publish more than a boolean to say that “this is acceptable research”. We should be asking reviewers to rate papers for their scientific contribution, their plausibility of correctness, their novelty, their honesty in citing previous work, etc. There is a good collection of recommendations on this for the Eurocrypt 2022 program committee. The change I might make is that instead of focusing on which papers to include, we focus on only eliminating the really bad papers, and publishing scores for the factors that we typically rank things on. This is in conflict with the tradition of computer science where a publication is essentially the same as a conference talk, because we don’t have enough speaking slots to accommodate all of the research being produced. I still think we need to adapt.
I’ve been reading a bit about ActivityPub and fiddling around with implementing some things. In doing so I’ve discovered that the standard was unfinished. There is a client-to-server part that doesn’t make a whole lot of sense, and a lot of the pieces are poorly defined. As an example, there are “activities” called Note and Article that are almost indistinguishable. The definition suggests that the difference is between a single paragraph and multiple paragraphs, but in reality people use “Note” with muliple paragraphs because “Article” is handled differently by some common platforms like mastodon. I think the standard has promise, but the way it’s going it will be badly fragmented.
Once social networks took off, the concept of blogging seemed less compelling. Now that the birdsite has descended into hell, I figured I’d investigate ActivityPub as an alternative. There are many ways to try this, including directly using mastodon or some other platform, installing the ActivityPub plugin for wordpress, or just writing my own activitypub server in python. I’m not sure which one will stick in the long run – they are all very fragile ecosystems.
I was amused to hear from my daughter that King county in Seattle is experiencing large increases in property taxes – in much the same way that California was experiencing rapidly rising property taxes during the 1970, which led to proposition 13 being passed. According to the legislative analyst, property tax rates in California prior to Proposition 13 were 2.67%, and Proposition 13 rolled those back to 1% of the cash value at the time of purchase. Perhaps more importantly, it limited the yearly increases to at most 2% per year, which over the long term, causes a large imbalance between the taxes paid by new owners and the taxes paid by long-term owners.
Property tax is unlike income tax, because it is more of a tax on wealth rather than income. On the other hand, when property values are increasing rapidly but property taxes are not, it results in a lower tax on capital gains from property (presumably some of those taxes are collected later from capital gains taxes when property is sold). Some people will rail against Proposition 13 for a variety of reasons – including the imbalance that it imposes, but also the impact it had on schools after the 1970s. My memory of the subject was that it was imposed as a way to reign in local authorities who could raise tax rates arbitrarily and give special breaks to insiders by rigging assessments. Now that property taxes are rising rapidly in King County, we might expect a similar backlash – perhaps another Proposition 13 style of revolt. Washington state is a peculiar case because it’s one of those states that has no income tax. This puts incredible pressure on the state to collect taxes from other sources (e.g., property tax and sales tax). The same is true in Texas, which has high property taxes but no income tax. By contrast, California has the highest state income tax rates.
The discussion about proposition 13 in California has been wrapped up in the perceived shortage of housing in the bay area, and the rising cost of housing. One reason is because proposition 13 provides an incentive not to move, because once you have lived in a house long enough, your taxes are going to be lower than what you would pay in a newly acquired property. There is evidence for this, though it’s not clear how much this effects the perceived housing shortage. People who retire and move into smaller housing might put increased pressure on entry-level housing, while freeing up larger family homes.
Another effect can be traced to another reason why Proposition 13 was passed – as cities like San Jose expanded rapidly in the 1970s, property taxes were also being raised to fund growth of the city. Since proposition 13, impact fees have replaced missing property tax revenue, which cause the cost of new housing to rise as the cost of growth for the city is born more heavily by new residents.
Proposition 13 has resulted in local government being restricted in how much tax they can collect from residential housing. As a result local government have an incentive to focus on commercial development rather than more housing development. I suspect this is a bigger impact than the lack of mobility in the housing market. It is showing up in the dual measures B and C that are on the ballot in San Jose, all over the development of this piece of land:
San Jose is already on the road to producing much more housing than it has in the past, but there is doubt that it will be enough to meet demand. One thing seems clear – California will be a much less desirable place for me to live in the future. Our infrastructure is already incredibly strained, and things like High Speed Rail will do almost nothing to solve our transportation problems as the population grows. The state is only nibbling at solutions to the problem, and I suspect that it will take much tighter restrictions on single occupancy vehicles in order to solve the problem.
There are two amendments to proposition 13 that are moving forward on the California initiative process. One of those would remove Proposition 13 protection for commercial property, and one is designed to increase mobility among seniors. Evidently only one of them is polling well enough to move forward. Total repeal of proposition 13 is still essentially unthinkable in California politics. I wouldn’t be surprised to see a similar thing happen in Washington.
I’ve always found tax policy a fascinating but very complicated subject. I started to become more aware of it when my marginal income tax rate topped 50% for the last decade or so. Ultimately taxes are collected to provide collective social welfare through the funding of a government. Some conservatives argue that government should not be involved in redistribution of resources, but there are some programs (e.g., national defense) that can only be funded through collective taxes. In the extreme, some conservative elements in the US appear to think that the poor should just die when they get sick. Most of the time I don’t resent the taxes that I pay, but there are limits to that tolerance. Most of the California budget is spent on education and health care, which seem like good investments in the health of a society. I’m less confident about how the federal government spends their revenue.
Posted inUncategorized|Comments Off on Another proposition 13?
Summary of a long post: politics to follow. Move on if it isn’t your thing.
In trying to understand how the USA arrived at the shitshow that Donald Trump and the Republican Party represent, I’ve started reading alternative news sources like
Fox News to compare with my usual rational source of the New York Times. I call it “Know thy enemy”, and I hope it will help me understand why so many people could vote against their own self interest for such an obvious moron. Part of the reason was the widespread hatred of Hillary – some of whom were clear sexists, but some also just didn’t believe she represented their interests. That still doesn’t explain why the Republican party holds both houses of Congress, and this should be our focus in the lead up to the 2018 election.
I have serious concerns that the Democratic party is headed down it’s own rat hole in pursuit of a progressive agenda that doesn’t have as much support as my fervent friends seem to believe. I previously gave the example of immigration, which I think mostly comes down to the difference between “illegal immigration” and “legal immigration”. Newt Gingrich thinks it is something that can allow Republicans to win, and we should beware of this. The Democratic party seems to have a blind spot on that issue – but also on other issues.
I recently came across two interesting articles on this. First, the New York Times opinion piece pointing out the wide gender disparity between support for the parties. Trump won among males, while Hillary won among females – by pretty wide margins. Moreover, this gap extends to the parties themselves, and there is some evidence that the gap is widening. A 2017 Pew study suggested that men prefer smaller government with fewer services, while women prefer the opposite. Another study found that men favor going to war to resolve disputes more than women do. This is actually my biggest objection to US foreign policy, and has been since the Vietnam war.
There are several ways to act upon this information. One way is to “double down on women”, the same way that Hillary tried to double down on the black vote. Another way is to try and understand what motivates men to favor Trump, and address some of their concerns. We would never win over all the racists and nazis, but elections are usually won by putting together coalitions who feel that their needs are better represented. In that light, it’s also interesting to read the transcript of a podcast from the Cato Institute, where they try to break down Trump voters into five different groups. I know that some of my friends will recoil in horror from the Cato Institute, since it was largely funded by the Koch brothers and represents the purest form of libertarianism. Just try to read the report and see if it offers any useful insight to understand the motivation. The poll might be flawed, but I found a lot of insight from it.
The first group of Trump voters was called the American preservationists (20%), and one issue that they are concerned about is immigration. I think we could win over some of them if we face the issue of legal vs illegal immigration, because they are largely working class and are being hoodwinked by the Republicans. They are the biggest group to think about.
The second group is the free marketers (25%). They just want small government, and this is the classical conversative/liberal divide on which I think the Democratic party has little to offer except possibly by controlling defense spending (e.g., the Afghanistan war that is leading nowhere).
The third group is the anti-elites (19%). I understand these the least, but they dislike it when people talk down to them. They probably hated Hillary’s connection to Goldman Sachs, and think Trump is a self-made man so he gets a bye.
The fourth group is the staunch conservatives (31%) – both social and economic. It’s possible that we might win some over by showing that Republicans are the ones who keep mushrooming the debt, but it’s a stretch.
The fifth group is disengaged (5%). They aren’t that motivated or informed, but if they vote, they vote on gut reaction to the candidates. The best way to appeal to them is probably to look less threatening. They share something in common with unmotivated democrats who lose interest in the candidate or the causes that the party is advancing. Every time I hear appeals to “people of color”, I wonder how white American preservationists would think about it. The Democratic party needs to lose the focus on identity and focus on real issues. Those issues might statistically matter more for people of color, but by identifying it as their issue, we exclude others who might care about the issues. It’s not about gender, race, age, or even class.
In the end I think it comes down to having a clear message on immigration and economic issues. We should stop wringing our hands on sexism and racism and religious bigotry – those people are unlikely to be swayed to the Democratic party, but they don’t really define why the Republicans are winning. The voting public is much more nuanced. Let’s grow the party rather than defining it narrowly.
Posted inUncategorized|Comments Off on An analysis of why Trump was elected
I'm also on Mastodon. I don't publish comments/conversation here, because there was too much spam. This gets pushed to the fediverse. If you want to discuss things, feel free to share on your preferred social media, or you can contact me via email to have private conversation


 Then there is the issue of why we have “volumes”. Why would we collect several issues together into a volume? Traditionally the notion of a “volume” corresponds to the year that it is published ToSC and TCHES even number their volumes as the year, but oddly some papers in
Then there is the issue of why we have “volumes”. Why would we collect several issues together into a volume? Traditionally the notion of a “volume” corresponds to the year that it is published ToSC and TCHES even number their volumes as the year, but oddly some papers in