For the last year I’ve been working on a new platform for publishing an open access academic journal. This is specifically motivated by the journal Communications in Cryptology, but ideally I’d like it to be useful for any journal that specifically accepts LaTeX. I should say up front that much of this work has been joint with Joppe Bos who has been wonderful to work with.
In the process of doing this project, I’ve learned a lot about the publishing process. It also caused me to understand why commercial publishers have managed to preserve their lock-in on academic publishing. Part of it is due to brand and the importance of reputation. Something like the Journal of Number Theory has been in existence since 1969, and the reputation of the journal has been built up over decades of performance. Once a journal is owned by an organization, it’s not easy to wrestle it away. There have been examples of this (e.g., the Journal of Algorithms, in which I had a paper long ago).
Software for publishing an open access journal
When we set out to start a new open access journal, I looked around for what software we could use. I spent a considerable amount of time evaluating Open Journal System (OJS). In my opinion this is by far the best option in 2023, but I still came to the conclusion that it really didn’t make sense for us to use it. There were several reasons:
- OJS incorporates a traditional model of reviewing, whereas we wanted to use a new reviewing model that is more common in computer science where papers are reviewed by a committee (and their identities are public).
- The software for OJS is written in PHP, and is about 26,500 lines of code at last count. The schema looks way too complicated for our needs, but still doesn’t support features that we want. Much of the important functionality is through third-party plugins, but support for these breaks frequently.
- OJS has only crude support for copy editing, and no native support for LaTeX.
- OJS is lagging somewhat on the capture of metadata. In particular they have no support for multiple affiliations after I reported the bug 30 months ago. This is partly due to the fact that it depends on a plugin and the schema is hard to evolve.
I think OJS deserves a lot of credit for changing the open access publishing landscape, and IACR uses it for two existing journals (TCHES and ToSC). They deserve a lot of credit for having advanced the open access landscape. I still think there are opportunities to improve in the future, but maybe not on that codebase. It has a lot of technical debt and is not adapting to the changing ways that people publish (for example, why are papers in PDF?).
A lot has been written about the cost structure for publishing a journal. Many journals from commercial publishers charge thousands of dollars for making an article open access. There are real costs associated with running an open access journal, but they don’t arise from IT costs of running servers. Most academic papers get very few readers, so a tiny $20/month website can hold hundreds of thousands of papers. The thing that costs real money is either the software development or the cost for any human labor. For more on this subject of the cost structure of a journal, I recommend reading this article.
Since I have donated my time for the last year to write software, it now appears that the cost structure for publishing a paper on cic.iacr.org will be about $5 plus the cost of copy editing (more on this later). One thing I noticed about OJS is that it is somewhat labor-intensive. Everything comes into the system through a form, and they assume that a human is entering the information. You might think authors do their job to enter correct information, but in my experience they don’t understand the importance of metadata to the reputation of their publications. Moreover, anything done by a human other than the author either has to be done as a volunteer or through paid labor. Since our goal is to drive the cost of publishing as low as possible, we sought ways to eliminate the need for human labor.
Architecture of our system
I wrote a paper with Joppe Bos earlier this year about how to incorporate metadata capture into LaTeX. We ended up publishing a shorter version of this paper in the TeX User’s Group journal (which is ironically only open access after an embargo). One goal of this work is to devise ways of using LaTeX so that authors can write their metadata directly into the paper, and have the system extract it in the process of publishing. This metadata goes straight into the indexing agencies and the website for hosting the papers. We believe that more publishers using LaTeX should adopt this strategy.
Our system is now about to launch for the journal “Communications in Cryptology“. The workflow for a journal has many steps, but roughly breaks down into three major pieces

Within these three clouds, there are multiple steps in the workflow, but they form the major parts and most importantly there is a clean transfer from one step to the next. Because of this, our system consists of three parts:
- A reviewing system (we currently use a modified version of hotcrp).
- A production and copy editing system that accepts LaTeX from authors and compiles it in the cloud. In the course of doing this it extracts all metadata (e.g., title, authors, affiliations, bibliography, abstract, funding, etc). This builds upon the work in our paper and our LaTeX style file is crucial to the process.
- A web hosting system that is relatively simple. We need to import papers and assign them DOIs, and we need to export metadata in various formats like OAI-PMH, RSS, and others.
The copy editing and production server is fairly complicated, since it has to run LaTeX in the cloud and keep track of feedback between copy editors and authors. The authors get a chance to view their LaTeX errors and make changes, and then it gets sent to the copy editor. We use a LaTeX log parser to extract the most important warnings and errors from the LaTeX log, and we inspect the references to make sure they have DOIs and other required elements. The author gets a set of items to respond to, and they can upload their final version.
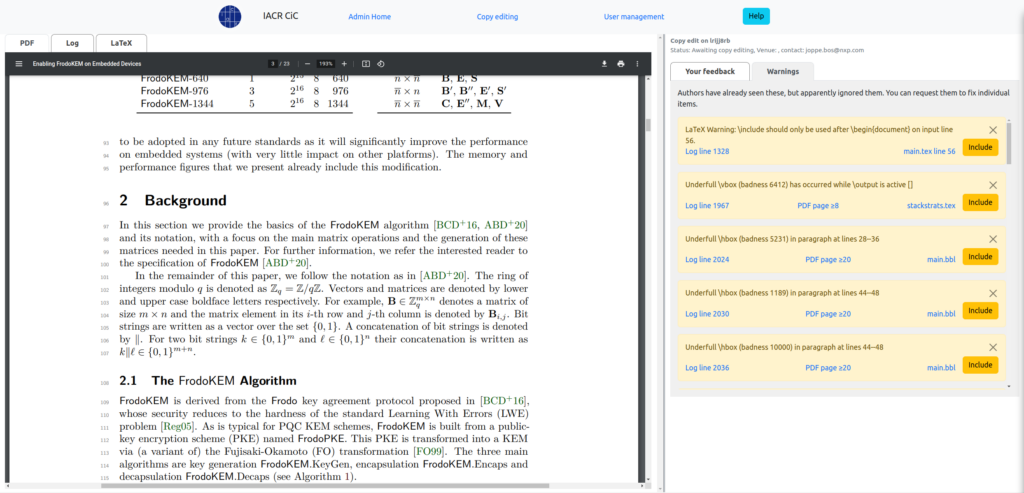
Once they upload their final revised version, the copy editor is presented with a view where they can view the changes to the PDF, the changes to the LaTeX sources, and the list of items the author was asked to change.
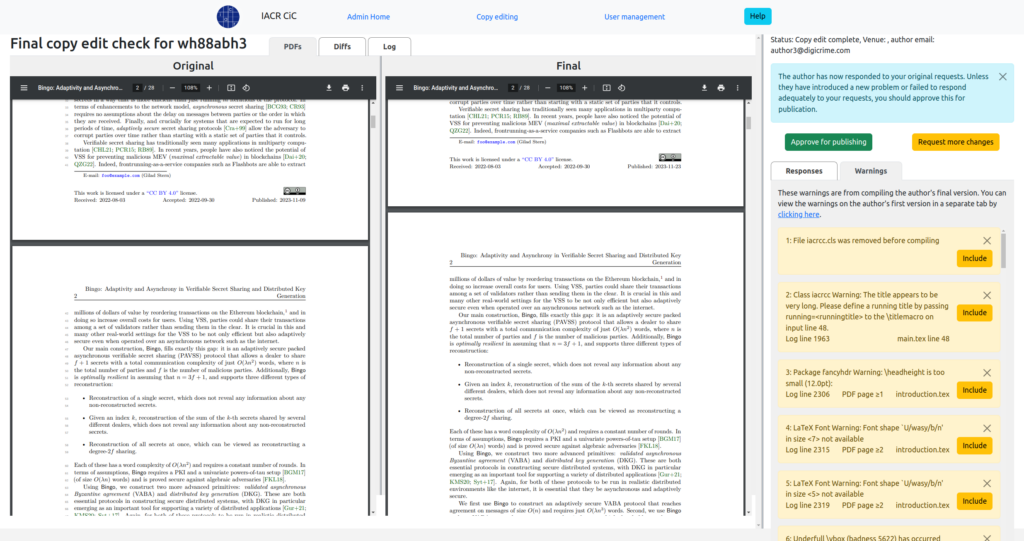
Once the author ↔ copy editor interaction is completed, the paper is finalized for publication. When an issue of final version papers has been collected, it gets forwarded to the hosting system where it is actually published. This transfer also constitutes the unit of archiving for an archiving service like LOCKSS.
The system we have built is not open source at this point, in part because I don’t want it to be used to simply improve profitability of commercial publishing. I undertook this venture to allow IACR to publish papers as cheaply as possible without access restrictions. Unlike some other societies that maintain a staff of people that have to be supported by selling publications from members, IACR has for years had volunteers who maintain the scientific programs though their volunteer effort. I’d like to see more scientific societies adopt open access policies and streamline their cost structure in the process.
@mccurleyThis looks like a great experiment! I find it sad it's not open source though. If the potential risk is reuse by commercial publishers, have you considered restrictive licenses like GNU AGPL, or Creative Commons with NC clause, or other licenses with clauses to exclude actors who don't give back?
I’m certainly not opposed to open source, and I might eventually release it if I see a reason to do so. So far I have avoided any package with a GPL license because I find it too restrictive. For example, I won’t use mysql-connector-python or MySQLClient. GPL is also incompatible with the LaTeX Project Public License, though I don’t think it matters because I invoke latex through docker. I find the whole license debate tiring. I don’t see any real risk from releasing it, but the thing I want to avoid is helping publishers that have various forms of closed access on publications. Unfortunately that includes some societies like ACM and AMS. I don’t know of any software license that could be used to enforce this and frankly I don’t want to think about it right now.